A research data pipeline refers to the systematic flow of data from its collection to its analysis and interpretation. In this blog post, we will delve into the crucial stages of defining a research data pipeline, and we will also highlight the assistance that HealthData.ai can provide throughout this process. These steps include defining a baseline, establishing inclusion and exclusion criteria, determining exposure and outcome measures, identifying relevant covariates, and considering the study size.
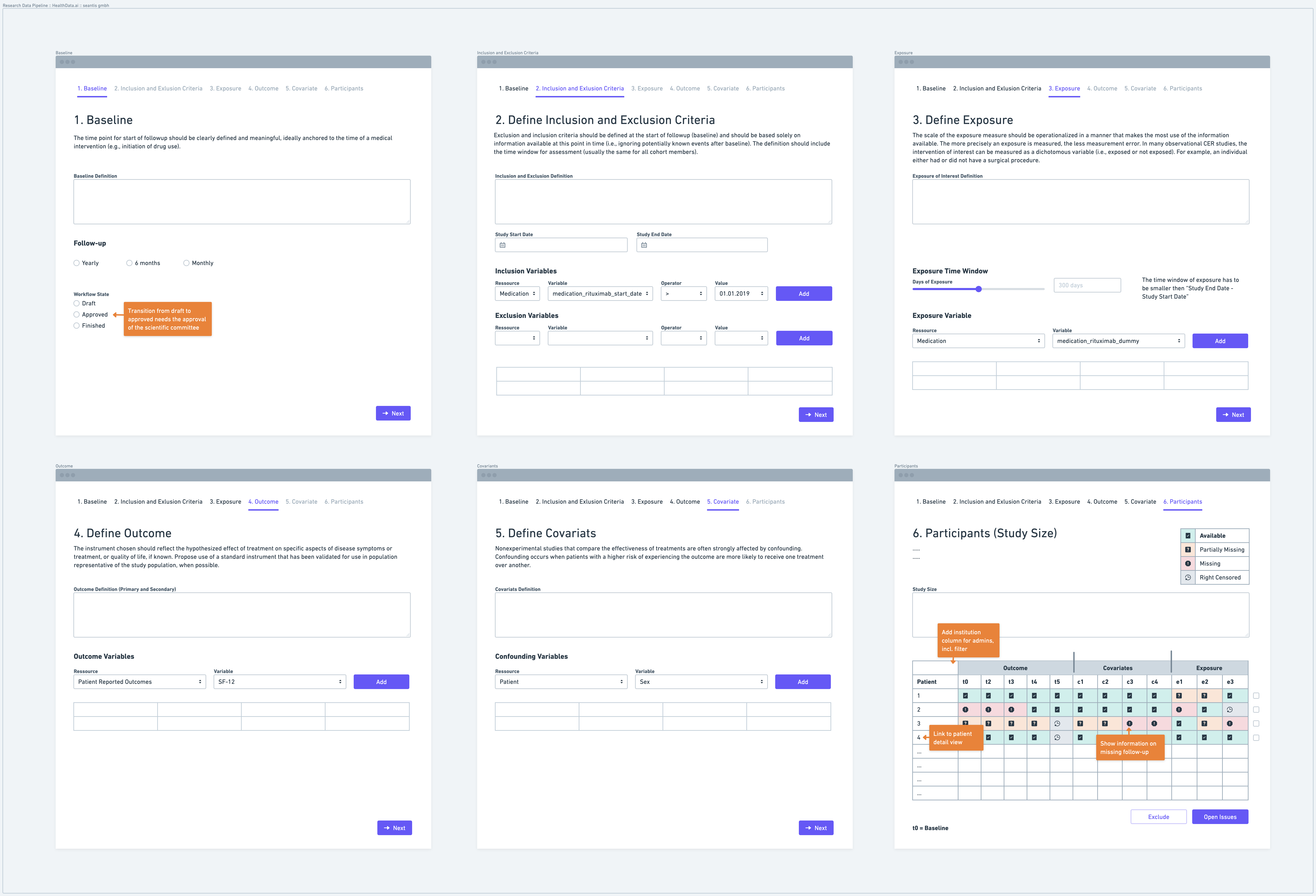
Step 1: Define a Baseline
Defining a baseline is the first step in establishing a research data pipeline. The baseline represents the starting point from which data collection and follow-up procedures begin. It is important to clearly define the time point or event that marks the baseline. For instance, the baseline could be the initiation of a specific medical intervention or the date of enrollment in a study. Defining the baseline ensures consistency and comparability across study participants.
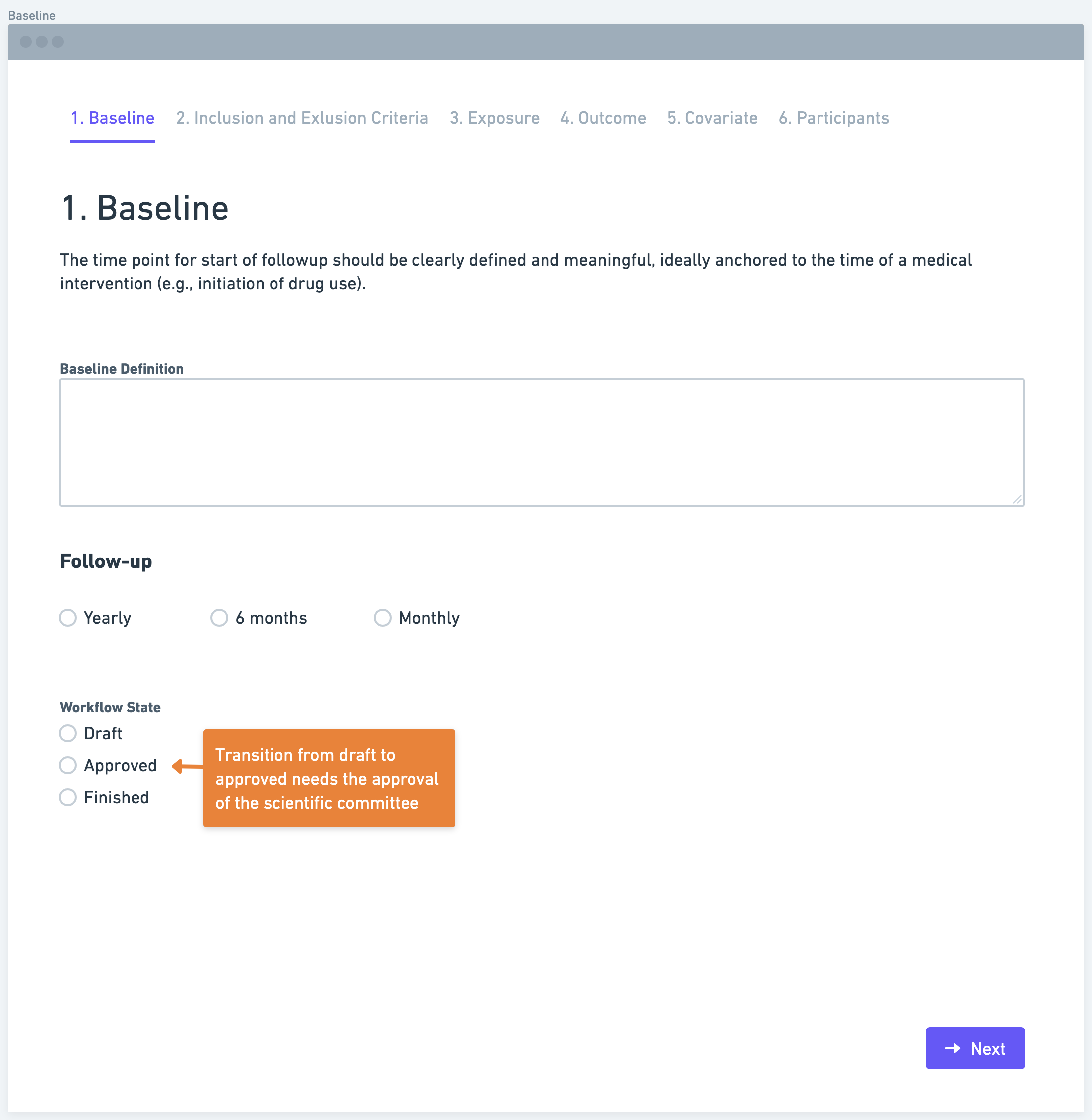
Step 2: Define Inclusion and Exclusion Criteria
After establishing the baseline, researchers need to define inclusion and exclusion criteria. Inclusion criteria outline the characteristics or factors that determine eligibility for participation in the study. Conversely, exclusion criteria specify the characteristics or factors that disqualify individuals from being included. These criteria should be based on information available at the baseline, disregarding any subsequent events. Clearly defining these criteria ensures the selection of a relevant and representative study population.
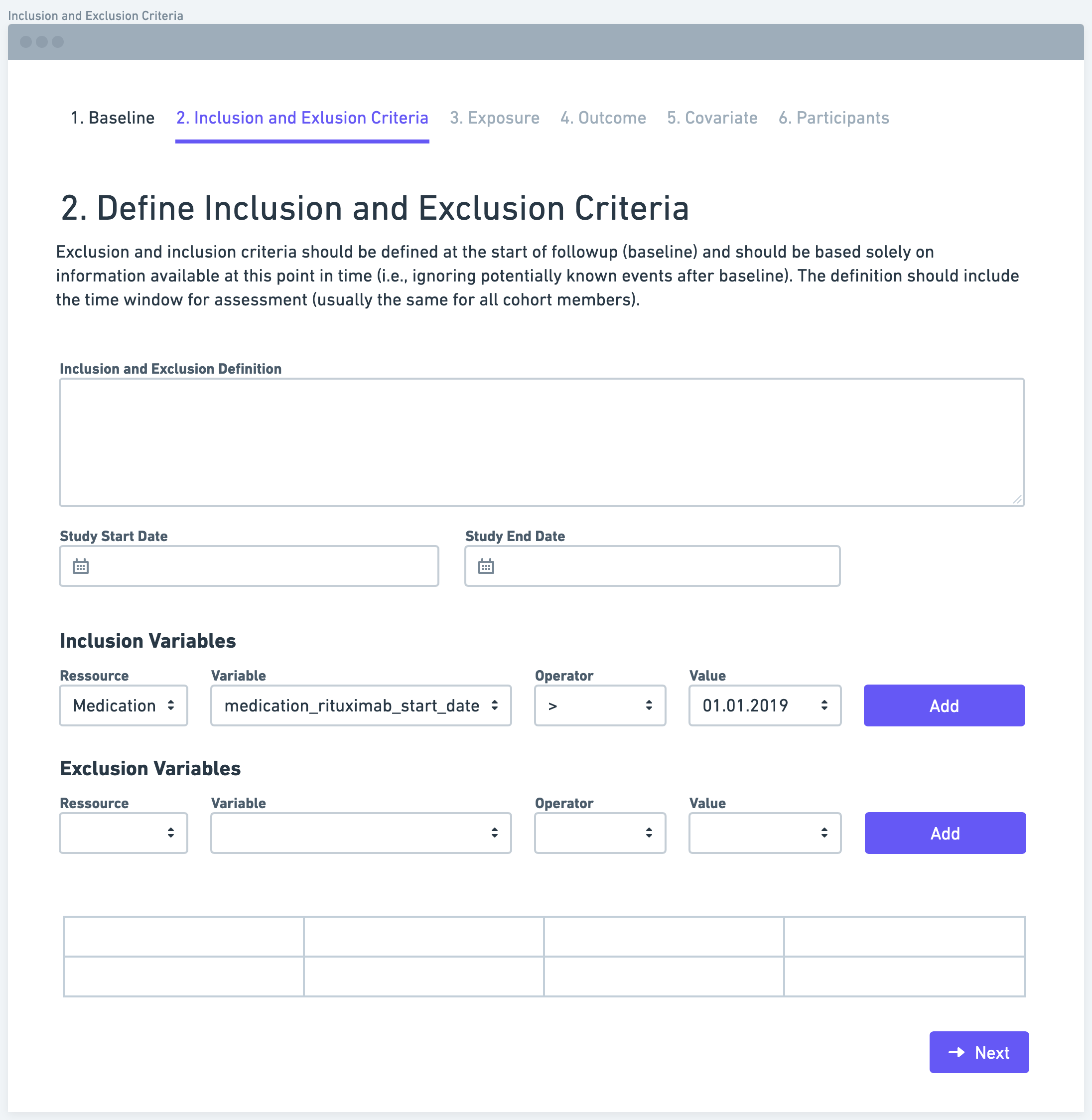
Step 3: Define Exposure
The next step is to define the exposure variable or measure. The exposure variable refers to the factor or intervention of interest that researchers want to study. It is important to operationalize the exposure measure in a way that maximizes the use of available information. This could involve categorizing the exposure as a dichotomous variable (e.g., exposed or not exposed) or using a more granular scale, depending on the research question and available data.
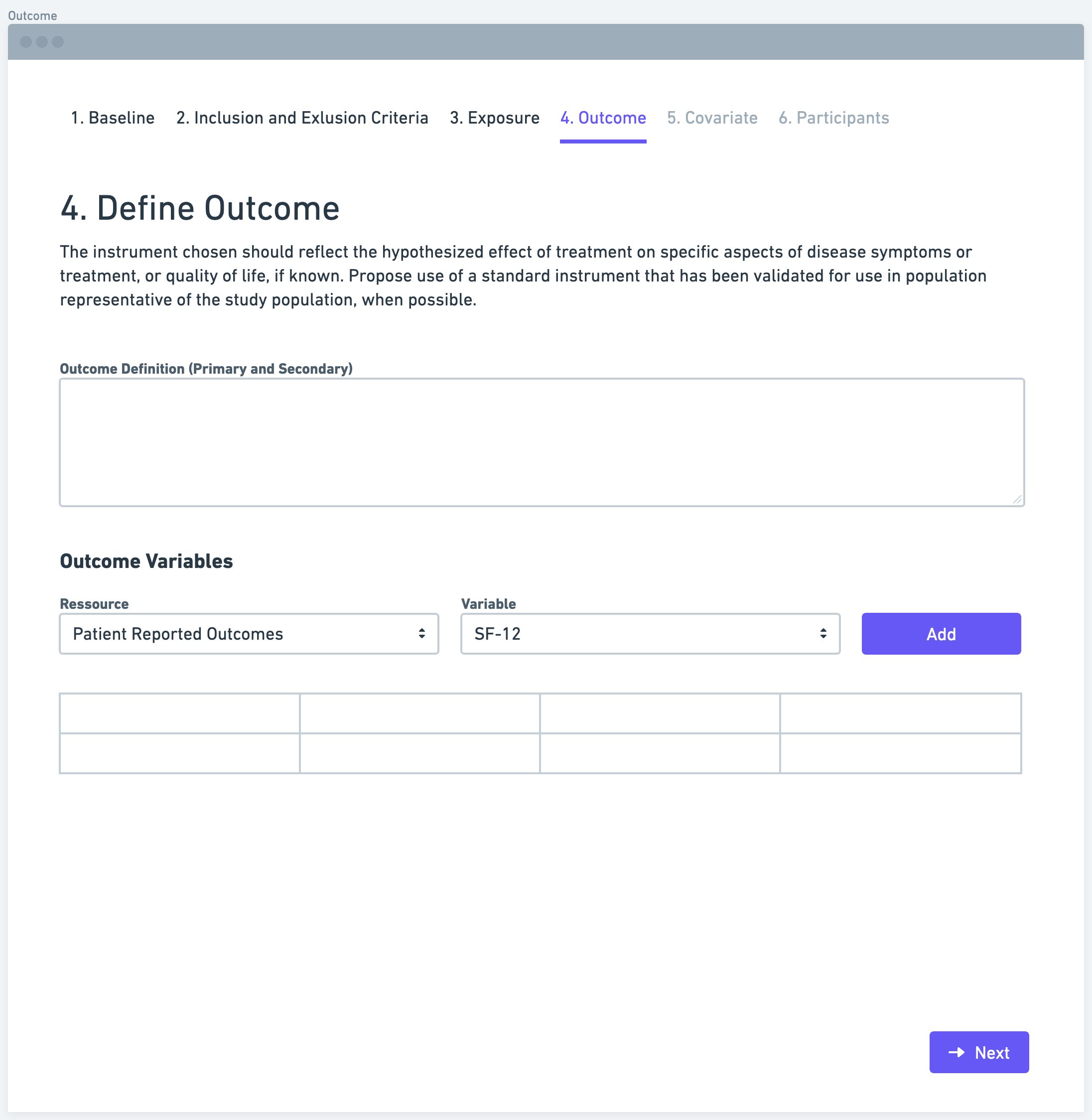
Step 4: Define Outcome
Defining the outcome variable is essential for studying the impact or effect of the exposure of interest. The outcome variable represents the specific endpoint or result that researchers want to measure or observe. It could be a clinical outcome, such as the occurrence of a disease or the improvement in a patient's health status. Clearly defining the outcome variable enables researchers to focus their data collection efforts and align their analyses accordingly.
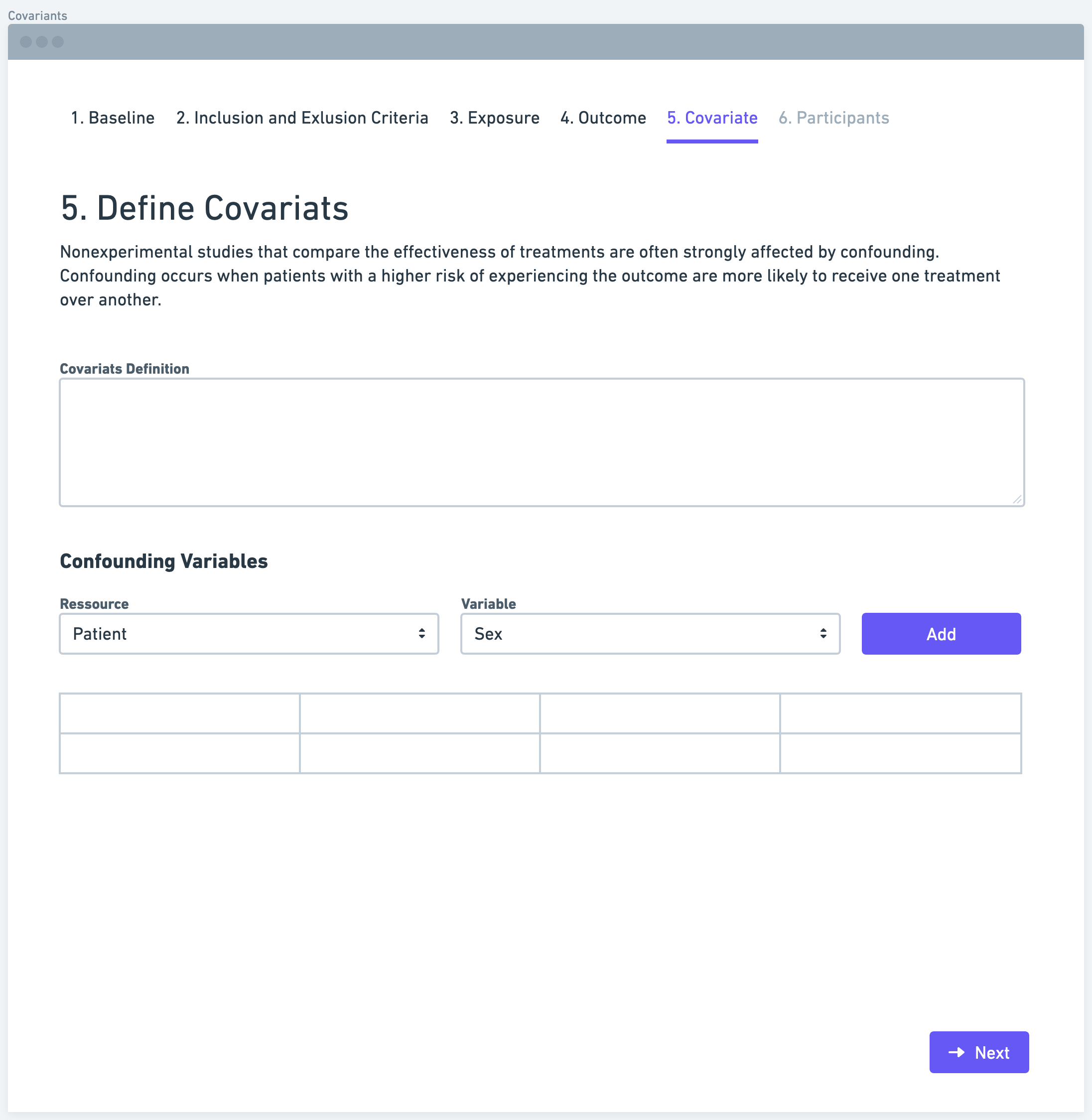
Step 5: Define Covariates
Covariates, also known as confounding variables, are additional factors that may influence the relationship between the exposure and outcome variables. It is important to identify and define relevant covariates that should be measured and controlled for in the study. These covariates can include demographic characteristics, medical history, lifestyle factors, or any other variables that might affect the relationship of interest. By considering covariates, researchers can minimize potential confounding and obtain more accurate results.
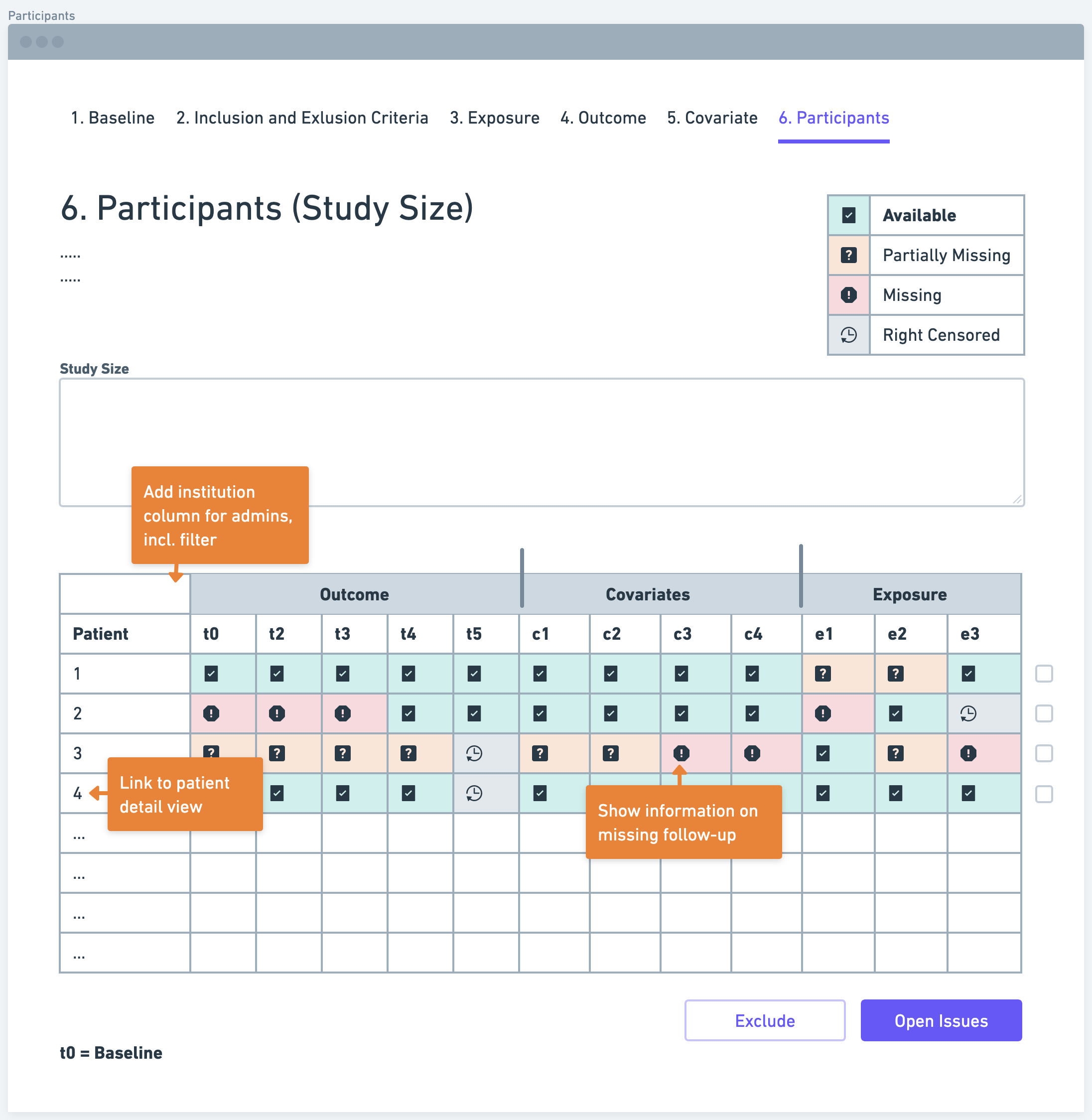
Step 6: Participants (Study Size)
Determining the study size is a crucial aspect of defining a research data pipeline. Researchers need to estimate the number of participants required to achieve sufficient statistical power and detect meaningful associations between the exposure and outcome variables. Various factors, such as the expected effect size, variability of the outcome, and significance level, need to be considered in sample size calculations. A larger sample size generally increases the study's precision and generalizability of findings.
Conclusion
Establishing a research data pipeline is a vital step in conducting effective research. By defining a baseline, establishing inclusion and exclusion criteria, defining exposure and outcome variables, identifying relevant covariates, and considering the study size, researchers can ensure the collection of high-quality and reliable data.
HealthData.ai is built to assist you in crafting a well-designed research data pipeline for your project, enabling you to contribute to evidence-based decision-making and propel scientific advancement.
Please reach out to Fabian Reinhard for additional details or to arrange a demo of the HealthData.ai Research Pipeline.
Recommend Reading: Developing a Protocol for Observational Comparative Effectiveness Research: A User’s Guide